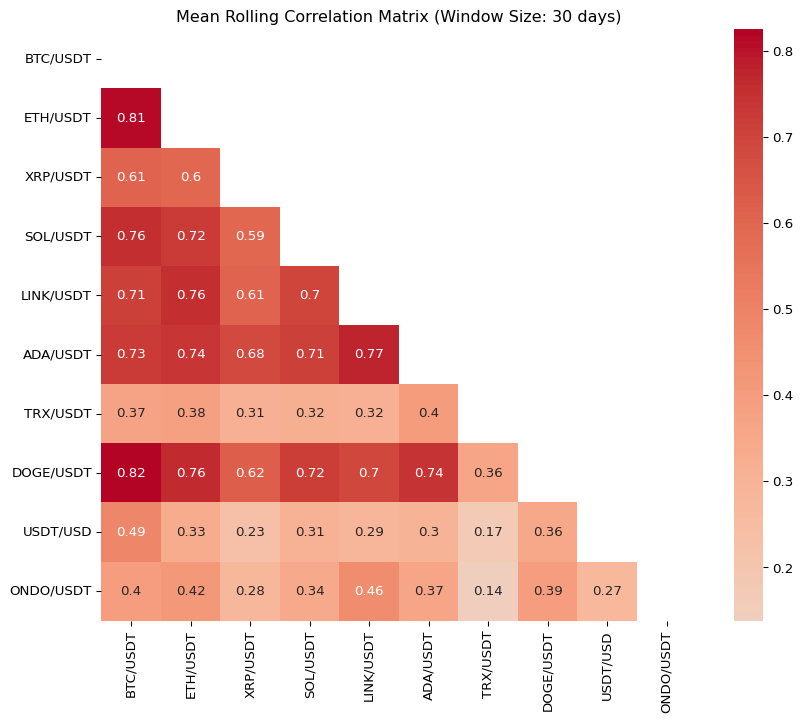
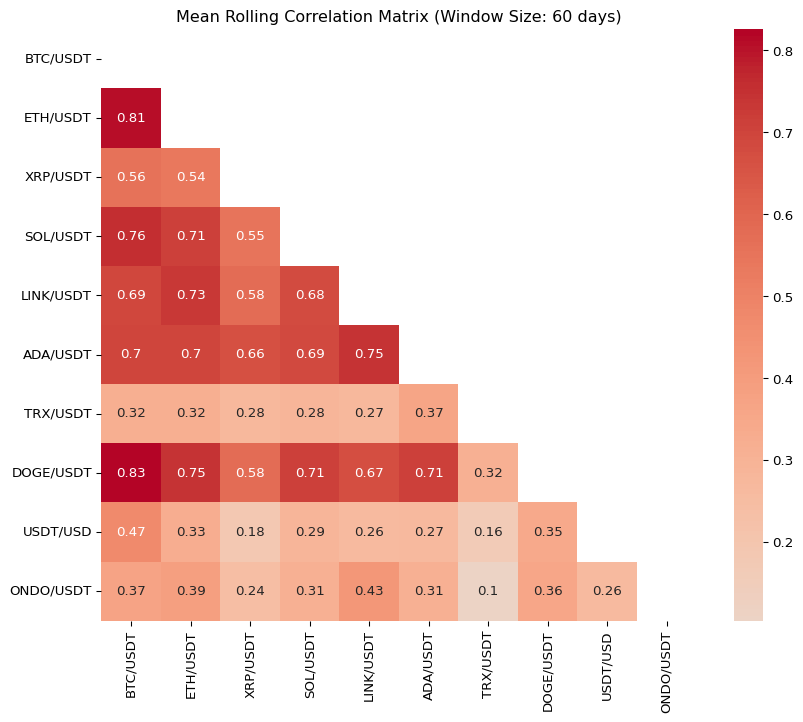
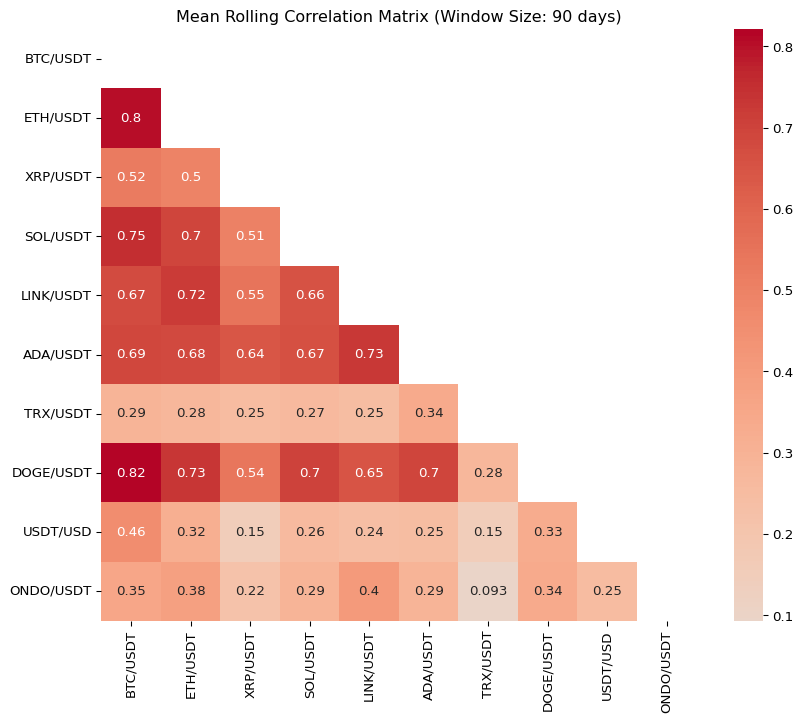
Abstract: 2025년 3월 현재, 시가총액이 크거나 투자자들에게 인기가 많은 주요 암호화폐(popular cryptocurrencies)를 선정하여 지난 1년간의 상관관계를 분석하였다. 대부분의 암호화폐 투자자들은 이러한 주요 암호화폐에 집중적으로 투자하는 경향이 있다. 한편, 암호화폐 자산에 대한 투자자의 평균 투자 기간은 단기(short-term)로, 일반적으로 1개월에서 3개월 사이에 해당한다. 이에 따라 본 연구에서는 데이터의 관측 빈도(observation frequency)를 일간(daily) 단위로 설정하고, 30일, 60일, 90일의 롤링 윈도우(rolling window)를 적용하여 주요 암호화폐 수익률의 선형 상관계수(Pearson’s coefficient)를 분석하였다. 이러한 분석은 변동성 헤징(volatility hedging)을 고려한 분산 투자(diversified investment) 전략 수립에 도움이 될 수 있다. 예를 들어, 일정한 투자 금액(예: 1억 원)을 주요 암호화폐 자산군 내에서 어떻게 배분할지 결정하는 데 있어, 상관계수 분석 결과가 투자 비중 조정에 유용한 정보를 제공할 것으로 기대된다.
DXY (미국 달러 지수)와 강한 음의 상관관계 (Coindesk 2023; Coinglass 2023). 만약 비트코인 가격이 달러 가격과 장기적으로도 반대 방향으로 움직인다면, 이는 비트코인이 인플레이션 헤지 자산으로 간주될 수도 있을 가능성을 나타낸다 (Dyhrberg 2021).
import matplotlib.pyplot as pltimport seaborn as snsimport numpy as np# 모든 행과 열이 출력되도록 설정pd.set_option('display.max_rows', None)pd.set_option('display.max_columns', None)pd.set_option('display.width', None)pd.set_option('display.expand_frame_repr', False)# 결과 출력 및 시각화for window, result in rolling_corr_results.items():# 상관 행렬을 DataFrame으로 변환 result_df = result.dropna(how='all')print(f"\n[Window = {window} days] Mean Correlation Matrix\n", result_df)# 히트맵 시각화 plt.figure(figsize=(10, 8))# 대각선 요소를 마스킹 mask = np.triu(np.ones(result_df.shape, dtype=bool)) sns.heatmap(result_df, annot=True, cmap='coolwarm', center=0, mask=mask) plt.title(f'Mean Rolling Correlation Matrix (Window Size: {window} days)') plt.show()
변수들의 관찰 주기 (단기? 장기?)에 따라 또는 관찰 시기 (10년전? 지금?)에 따라 변수들 간의 선형관계는 유지되지 않을 수 있습니다. 2025년 현재 비트코인 (BTC) 가격은 시장 심리, 규제 변화, 기술적 요인 등에 크게 영향을 받고 있습니다.
상관계수가 낮은 암호화폐 자산 조합을 식별하고, 헤지 투자 전략을 논의.
특정 암호화폐 간의 높은 상관관계가 나타나는 이유 및 그에 따른 리스크 분석.
2024년 3월부터 2025년 2월까지 암호화폐 시장에 큰 영향을 미친 주요 변화 시기와 원인:
비트코인 반감기 (2024년 4월 20일): 비트코인 채굴 보상이 6.25 BTC에서 3.125 BTC로 절반으로 감소. 이는 비트코인의 공급 감소로 이어져 가격에 상승 압력을 가함.
비트코인 ETF 자금 유입 증가 (2024년 10월): 비트코인 ETF로의 지속적인 자금 유입이 관찰됨. 10월까지 ETF 투자자들이 총 345,200 BTC(200억 달러 이상의 가치)를 매입.
트럼프의 대통령 당선 (2024년 11월): 도널드 트럼프가 “암호화폐 대통령”이 되겠다는 공약을 내세우며 당선됨. 이는 암호화폐 시장에 대한 긍정적인 기대감을 불러일으킴.
EU의 암호화폐 시장 규제(MiCA) 전면 시행 (2024년 12월 30일): 유럽연합에서 암호화폐 시장 규제(MiCA)가 전면 시행됨. 이로 인해 EU 전역에서 암호화폐 서비스 제공업체들에 대한 통일된 규제 프레임워크가 적용되기 시작.
트럼프의 암호화폐 정책 발표 (2025년 1월): 트럼프 대통령이 취임 후 미국을 “암호화폐의 수도”로 만들겠다는 계획을 발표함. 여기에는 비트코인 전략적 비축 등의 아이디어가 포함됨.
stars and bins에서 위의 변화 시기가 bins 역할을 한다는 가정하여, 기간 stars을 다음과 같이 나누어 상관관계를 conditional 해 본다.
20224년 3월 1일 (관측기간 시작일) - 2024년 4월 20일
2024년 4월 21일 - 2024년 9월 30일
2024년 10월 1일 - 2024년 11월 5일
2024년 11월 6일 - 2024년 12월 31일
2025년 1월 1일 - 2025년 2월 28일 (관측기간 종료일)
변화를 \(Z\)로 표기했다면, covariance decomposition formula에 의해,
(추후 계속)
4 부록: Conditioning Theorems in Probability Theory
4.1 Adam’s Law: Smoothing Property of Conditional Expectation
Also known as the Law of Total Expectation or Law of Iterated Expectations.
If \(X\) is a random variable whose expectation \(E(X)\) is defined and \(Z\) is any random variable defined on the same probability space, then: \[E(X) = E(E(X|Z)).\]
A conditional expectation can be viewed as a Radon–Nikodym derivative, making the tower property a direct consequence of the chain rule for conditional expectations.
A special discrete case: If \(\{Z_{i}\}\) is a finite or countable partition of the sample space, then: \[E(X) = \sum_{i} E(X \mid Z_i)P(Z_i).\]
4.2 Eve’s Law: Variance Decomposition Formula
Known as the Conditional Variance Formula or the Law of Iterated Variances.
If \(X\) and \(Y\) are random variables defined on the same probability space, and if \(Y\) has finite variance, then:
This is a special case of the covariance decomposition formula.
Applications
분산 = “(조건부 분산)의 평균” + “(조건부 평균)의 분산”
Analysis of Variance (ANOVA): Variability in \(Y\) splits into an “unexplained” within-group variance and an “explained” between-group variance. The F-test examines if the explained variance is significantly large, indicating a meaningful effect of \(X\) on \(Y\).
Linear Regression Models: The proportion of explained variance is measured as \(R^2\). For simple linear regression (single predictor), \(R^2\) equals the squared Pearson correlation coefficient between \(X\) and \(Y\).
Machine Learning and Bayesian Inference: In many Bayesian and ensemble methods, one decomposes prediction uncertainty via the law of total variance. For a Bayesian neural network with random parameters \(\theta\): \(\operatorname {Var} (Y)=\operatorname {E} {\bigl [}\operatorname {Var} (Y\mid \theta ){\bigr ]}+\operatorname {Var} {\bigl (}\operatorname {E} [Y\mid \theta ]{\bigr )}\) often referred to as “aleatoric” (within-model) vs. “epistemic” (between-model) uncertainty
Information Theory: For jointly Gaussian \((X,Y)\), the fraction \(\operatorname {Var} (\operatorname {E} [Y\mid X])/\operatorname {Var} (Y)\) relates directly to the mutual information \(I(Y;X)\). In non-Gaussian settings, a high explained-variance ratio still indicates significant information about Y contained in X
Example 1 (Exam Scores): Suppose students’ exam scores vary between two classrooms. The variance of all scores (\(Y\)) can be decomposed into the variance within classrooms (unexplained) and the variance between classroom averages (explained), reflecting differences in teaching quality or resources.
Example 2 (Mixture of Two Gaussians): Consider \(Y\) as a mixture of two normal distributions, where the mixing distribution is Bernoulli with parameter \(p\). Suppose:
This relationship is a particular instance of the general Law of Total Cumulance and is crucial for analyzing dependencies among variables conditioned on a third variable or groupings.
4.4 Bias-Variance Decomposition of MSE
Key: The Bias-Variance Decomposition emphasizes the trade-off between making \(\hat{Y}\) reliably close to its own expected value (low variance) and aligning that expected value with the true target \(\mathbb{E}[Y]\) (low bias).
In many estimation or prediction settings, we have a random outcome \(Y\) and an estimator (or model prediction) \(\hat{Y}\). The Mean Squared Error (MSE) of \(\hat{Y}\) is:
If we decompose \(\hat{Y}\) around its expected value, we can split MSE into a bias term and a variance term (plus any irreducible noise in certain contexts). Formally, assume
Here, if there is additional irreducible noise, it appears as a separate constant term. This decomposition closely aligns with the Law of Total Variance (Eve’s Law) in the sense that the total mean squared difference can be split into a “spread around the estimator’s mean” plus the “squared difference of that mean from the true value,” mirroring how variance itself decomposes into conditional components.