2D Relationship
합리적 분석 흐름: 수치 요약 → 시각적 탐색 → 구조 해석 → 단위 해석 (탄력성)
현실 세계의 대부분의 분석 대상은 하나의 변수로 설명되지 않습니다. 중요한 구조는 두 변수 이상 간의 관계에서 나타나며, 이러한 관계의 형태와 강도를 파악하는 것이 데이터 분석의 핵심입니다.
1 2D 시각화의 중요성
숫자만으로는 파악할 수 없는 구조를 시각적으로 드러내는 것이 산점도(scatterplot)입니다. 두 변수의 관계를 점으로 표시함으로써, 관계의 방향성, 선형성, 변동성, 이상값(outlier) 등을 직관적으로 파악할 수 있습니다. 이를 보다 정교하게 확장한 것이 Joint Plot으로, 각 변수의 단변량 분포와 이변량 산점도를 동시에 보여줍니다. 분포의 왜도(skewness), 집중도, 변동성을 함께 파악할 수 있어 강력한 시각화 도구입니다. 특히 Anscombe’s quartet은 시각화의 필요성을 강조하는 대표적 사례입니다. 네 개의 데이터셋이 동일한 평균, 분산, 상관계수, 회귀선을 가지지만, 시각화해 보면 전혀 다른 구조임을 확인할 수 있습니다. 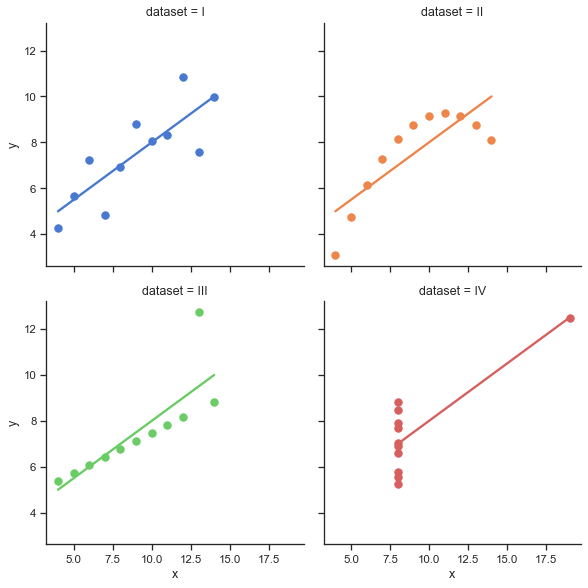
Anscombe’s quartet. 이처럼 수치는 관계의 정량적 요약을 가능하게 하지만, 그 구조를 정확히 이해하기 위해서는 시각화가 필수입니다.
2 상관관계와 인과관계는 다릅니다
상관관계(correlation)는 단지 함께 움직이는 경향(co-movement)을 수치적으로 표현한 것이며, 인과관계(causation)와는 전혀 다른 개념입니다. 상관계수는 다음과 같이 계산됩니다:
\[\rho_{X,Y} = \frac{\mathrm{Cov}(X, Y)}{\sigma_X \sigma_Y}\]
이는 두 변수 간의 선형 관계의 강도와 방향을 측정할 뿐이며, \(|\rho| = 1\)이면 완벽한 선형 관계, \(\rho = 0\)이면 선형성이 없음을 의미합니다. 하지만 상관관계는 결코 인과관계(causality)를 보장하지 않습니다.
예를 들어 운동화 가격과 교수의 월급이 모두 시간이 흐름에 따라 증가하고 있다면, 상관계수는 높게 나올 수 있지만 이 둘 사이에는 직접적 인과관계가 없으며, 이는 단지 공통된 시간 추세(time trend)의 영향일 수 있습니다. 이러한 경우는 허위 상관관계(spurious correlation)로 분류됩니다.
또한, 두 변수 간에 세 번째 요인(third variable)이 존재할 경우, 상관계수는 실제 인과 구조를 왜곡할 수 있습니다. 예를 들어, 교육 수준과 소득 간에는 상관관계가 관찰되지만, 이 관계는 가정환경, 건강, 지역, 사회 자본 등 다양한 변수의 영향을 받을 수 있습니다.
이 때문에 인과관계를 분석하려면 단순한 상관계수를 넘어 모형 기반 추정(structural modeling), 혼란변수 통제(confounder control), 또는 실험적 설계(experimental design)가 필요합니다.
3 해석이 쉬운 관계와 어려운 관계
3.1 단기적·선형적 관계
시간의 개입이 거의 없거나, 실험적 통제가 가능한 경우, 또는 물리적으로 정의된 상황에서 특정 변수 간의 관계는 선형 관계로 관측될 수 있습니다. 이러한 관계는 보통 산점도에서도 직선에 가깝게 나타나며, 회귀분석 결과도 안정적입니다. - 키와 몸무게 - 용수철의 늘어난 길이와 매달린 추의 무게 (후크의 법칙) - 중간고사 점수와 기말고사 점수 - 주식 시장의 하루 전 거래량과 당일 거래량
이러한 관계는 cross-sectional 데이터 또는 단기적 시간관측자료에서 자주 등장하며, 분석과 해석이 비교적 쉽습니다. 그러나 대부분 단순한 기술적 이해에 그치며, 사회과학적 의사결정이나 정책 수립에는 한계가 있습니다.
3.2 장기적·비선형적 관계
반면 사회적, 경제적, 제도적 요소들이 복잡하게 얽혀 있는 장기 관계는 해석이 어렵습니다. 이 경우는 수많은 혼란 요인(confounder), 피드백 효과, 동태적 변화 등이 작용하여 단순한 회귀선이나 상관계수로는 충분히 설명되지 않습니다:
- 교육 수준과 장기적 연평균 소득
- 국가별 자유무역 정책과 경제 성장률
- 흡연과 건강 지표
- 기후정책과 장기 에너지 소비량
이런 관계들은 정책적 판단이나 경제적 해석에서 매우 중요하지만, 대부분 비선형적 구조를 가지며, 설명변수와 종속변수 간에 시간 지연(lag), 누적 효과, 상호작용 효과가 존재합니다. 또한 국가 간, 세대 간, 제도 간의 이질성까지 고려해야 하므로, 단순 상관계수 해석은 거의 무의미하다고 볼 수 있습니다.
4 로그 변환을 통한 비선형 관계의 선형화
경제 변수들은 곱셈적(multiplicative) 관계를 갖는 경우가 많으며, 이러한 구조는 선형 회귀모형에 부적합합니다. 이때 사용하는 대표적 방법이 로그 변환(log transformation)입니다.
예를 들어 다음과 같은 관계를 생각해 봅니다:
- 임금이 5%씩 증가할수록, 소비량도 비례적으로 증가
- 물가가 2배로 오르면, 실질 수요량이 20% 감소
이런 곱셈 구조는 로그를 취하면 덧셈 구조로 바뀌며, 회귀모형 내에서 선형화됩니다:
\[\log Y = \alpha + \beta \log X + \varepsilon\]
이 형태에서 \(\beta\)는 탄력성(elasticity)으로 해석됩니다.
탄력성(elasticity)은 \(X\)가 1% 변화할 때 \(Y\)가 몇 퍼센트 변하는지를 나타내는 경제학적 해석 지표입니다. 로그-로그 회귀모형에서 탄력성은 다음과 같이 정의됩니다:
\[\text{Elasticity} := \frac{\partial \log Y}{\partial \log X} = \beta\]
즉, \(\beta\)는 \(X\)가 1% 변화할 때 \(Y\)가 \(\beta\)%만큼 변화함을 의미합니다.
- 소득 탄력성: 소득이 1% 증가할 때 소비가 몇 % 증가하는가?
- 재산 탄력성: 총자산이 증가할 때 비소비적 지출(예: 투자, 저축)이 얼마나 증가하는가?
- 수요의 가격탄력성: 가격이 1% 증가할 때 수요는 몇 % 감소하는가?
이 개념은 단기적 관계뿐 아니라 장기적 구조 추정(long-run structural estimation)에서 매우 중요한 해석을 제공합니다. 단순한 절대 변화가 아닌 상대적 비율의 변화를 분석한다는 점에서 경제지표에 특화된 해석도구입니다.