1D Statistics and Plots
“우리는 숫자보다 숫자의 패턴을 읽어야 합니다”
수치는 정밀함을 제공하고, 시각화는 구조적 직관을 제공합니다. 수익률 데이터처럼 크기와 분산, 방향성과 꼬리 두께까지 고려해야 하는 경우, 두 도구는 함께 사용하는 것이 유용합니다. 예컨대, 평균 수익률이 같다고 해도 표준편차, 왜도, 첨도, 이상값의 유무에 따라 투자자의 판단은 전혀 달라질 수 있습니다.
두 자산, 삼성전자와 SK하이닉스 주식의 최근 24개월간 월간 수익률 데이터를 비교해 봅니다. 같은 시장에서 거래되는 두 종목이라도 수익률의 크기, 변동성, 비대칭성은 매우 다를 수 있습니다. 이 비교를 통해 우리가 알고 싶은 것은 단순히 “어느 쪽 수익률이 더 높은가?”가 아닙니다. 중요한 질문은 다음과 같습니다:
- 수익률의 대표값은 어느 쪽이 더 높은가?
- 더 안정적인 종목은 무엇인가?
- 이상치(outlier)는 존재하는가?
- 수익률 분포는 정규분포처럼 대칭적인가?
이러한 질문에 합리적으로 답하기 위해 필요한 도구가 바로 수치 요약(Statistics)과 시각화(Plots)입니다.
1 수치로 요약하기: Statistics
1.1 중심 경향의 측정
- 평균 (mean): 수익률의 총합을 관측치 수로 나눈 값. 그러나 극단값(outlier)에 민감합니다.
- 중앙값 (median): 데이터를 정렬했을 때 중간에 위치한 값. 비대칭 분포에서 더 안정적인 대표값입니다.
- 최빈값 (mode): 가장 자주 등장한 값. 분포의 패턴이 뚜렷한 경우 유용합니다.
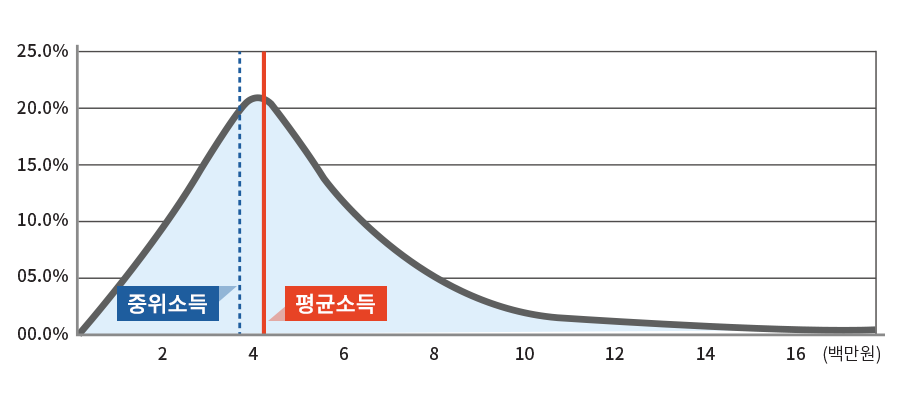
예: 고소득자의 존재로 인해 평균소득이 높아진 분포에서는 중앙값이 오히려 실제 중간소득층을 더 잘 대표합니다. 이처럼 소득분포는 대개 오른쪽으로 긴 꼬리를 가진 비대칭 분포를 보입니다.
1.2 산포의 측정과 변동성의 해석
- 표준편차 (standard deviation)는 평균으로부터 값들이 얼마나 퍼져 있는지를 나타냅니다. 분산의 제곱근입니다.
- RMS (Root Mean Square)는 값들의 크기를 평균적으로 평가하며, 평균이 0일 때에도 유용합니다.
\[\text{RMS} = \sqrt{\frac{1}{n} \sum_{i=1}^n x_i^2}, \quad s = \sqrt{\frac{1}{n-1} \sum_{i=1}^n (x_i - \bar{x})^2}\]
수익률이 평균 0에 가까워도 변동성이 크면 RMS는 여전히 크며, 이는 평균 수익률 (mean return)이 같아도 변동성(volatility)이 다르다는 점을 반영합니다.
1.3 분포의 모양: 왜도와 첨도
왜도 (skewness)는 분포의 비대칭성을 나타냅니다. 오른쪽 꼬리가 길면 양의 왜도, 왼쪽이 길면 음의 왜도입니다.
첨도 (kurtosis)는 분포의 뾰족함과 꼬리의 두께를 설명합니다. 정규분포보다 꼬리가 두꺼우면 극단값의 발생 가능성이 높습니다.
예를 들어, 시가총액이 작은 주식들(small size)의 수익률이 시가총액이 큰 주식들(big size)보다 평균적으로 더 높을 수 있습니다. 그러나 small size 주식의 수익률 분포가 더 큰 왜도(skewness)와 더 높은 첨도(kurtosis)를 가진다면, 해당 주식에 투자한 투자자는 높은 기대수익률과 함께 더 큰 변동성 및 극단적 손익 가능성을 동시에 감수해야 합니다.
이러한 현상은 “more risk, more return”이라는 주류 금융경제학 이론의 핵심 철학과도 일치합니다. 특히 자산 가격 결정 이론에서는, 평균 수익률이 높은 자산은 일반적으로 더 큰 분산(variance), 더 긴 꼬리(tail), 더 뾰족한 분포(peakedness)를 동반한다고 가정합니다. 이는 왜도와 첨도가 단순한 통계량이 아니라, 자본시장에서 보상(risk premium)이 형성되는 구조를 이해하는 데도 중요한 역할을 함을 의미합니다.
1.4 자유도와 통계적 추정의 정확성
자유도(degree of freedom)는 통계적 추정에서 독립적인 정보가 얼마나 있는가를 수량화한 개념입니다.
표준편차를 계산할 때, 전체 편차 합이 0이 되기 때문에 마지막 하나는 나머지로부터 결정됩니다. 따라서 \(n\)개의 편차 중 자유로운 값은 \(n-1\)개입니다. 이 때문에 분산 계산에서 분모가 \(n\)이 아닌 \((n-1)\)이 되는 것입니다.
선형회귀에서는 자유도가 더욱 중요한 의미를 가집니다.
T-통계량(T-statistic)은 회귀계수가 0이라는 귀무가설을 검정할 때 사용됩니다. 이때의 자유도는 \(n - k - 1\)입니다. 여기서 \(k\)는 독립변수의 수이며, 1은 상수항(intercept) 때문입니다.
\[t = \frac{\hat{\beta}_j}{\text{SE}(\hat{\beta}_j)}, \quad \text{with df} = n - k - 1\]Adjusted R-squared (조정된 결정계수)도 모델의 설명력을 평가할 때 자유도를 고려하여 계산됩니다. 단순한 R-squared는 변수의 수를 늘릴수록 무조건 커지기 때문에, 다음과 같이 자유도로 보정합니다: \[ \bar{R}^2 = 1 - \left(1 - R^2\right) \cdot \frac{n - 1}{n - k - 1} \]
이는 변수의 수가 증가할수록 모델이 더 복잡해지지만, 자유도가 줄어드는 만큼 설명력에 대한 과도한 낙관을 억제하려는 구조입니다. 이처럼 자유도는 통계적 추정의 신뢰성, 검정의 엄밀함, 모델 선택의 합리성에 직결되는 핵심 개념입니다.
2 그림으로 보기: Plots
2.1 히스토그램과 밀도 해석
히스토그램(histogram)은 데이터를 구간별로 나누고 각 구간의 빈도수를 막대그래프로 표현한 것입니다. 단순한 수치보다 분포의 모양을 직관적으로 파악할 수 있습니다.
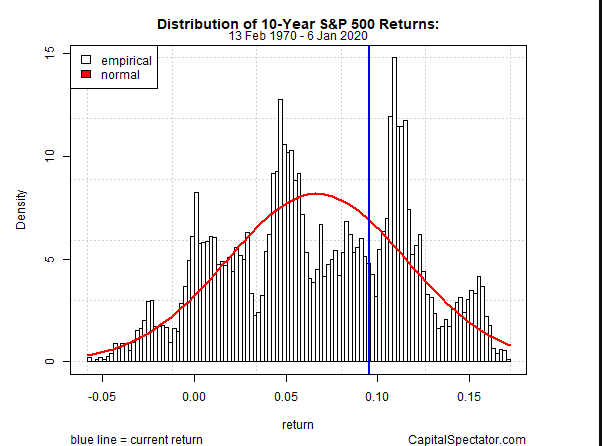
히스토그램은 확률 밀도(probability density)의 개념으로도 해석할 수 있습니다. 관측치가 많아질수록 히스토그램은 연속적인 확률 밀도 함수에 수렴하며, 특히 로그변환이나 비율 변화율(퍼센트 변화)을 적용하면 비대칭 구조를 완화할 수 있습니다.
2.2 Boxplot: 중앙값, 사분위수, 이상값
상자그림(Boxplot)은 데이터를 5개의 지점(최소, Q1, 중앙값, Q3, 최대)으로 요약합니다. 이상값은 박스 밖의 점으로 나타납니다.
- IQR(Interquartile Range)이 크면 변동성이 크다는 뜻입니다.
- 박스가 한쪽으로 치우쳐 있으면 분포가 비대칭임을 나타냅니다.
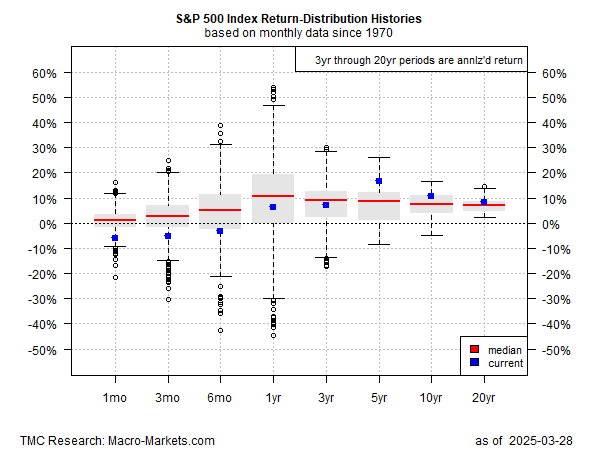
Boxplot은 특히 변수 간 비교에서 수익률의 위치와 분산을 동시에 시각화할 수 있는 장점이 있습니다.